The compiler, an optimization beast. The luxury of “just let the compiler do it,” comes from decades of passed down knowledge. But beware. Just because compilers are good at there jobs, doesn’t mean programmers shouldn’t be aware of what they spit out.
Let’s start by looking at the following code and generated assembly:
Struct32 s32 = default;
for (int i = 0; i < cache.Length; i++)
{
cache[i] = s32;
}L0000: sub rsp, 0x48
L0004: vzeroupper
L0007: vxorps ymm0, ymm0, ymm0
L000b: vmovdqu [rsp+0x28], ymm0
L0011: xor eax, eax
L0013: mov rcx, [rcx+8]
L0017: cmp dword ptr [rcx+8], 0
L001b: jle short L0040
L001d: mov rdx, rcx
L0020: cmp eax, [rdx+8]
L0023: jae short L0048
L0025: mov r8d, eax
L0028: shl r8, 5
L002c: vmovdqu ymm0, [rsp+0x28]
L0032: vmovdqu [rdx+r8+0x10], ymm0
L0039: inc eax
L003b: cmp [rcx+8], eax
L003e: jg short L001d
L0040: vzeroupper
L0043: add rsp, 0x48
L0047: ret
L0048: call 0x00000170375500a8
L004d: int3Simple stuff here. If you look at the lines (14 and 15) we can see the actual assignment is done in just two instructions. The first instruction copies the entire Struct32 into the ymm0 register. Then the second copies the contents of the ymm0 into the array. The compiler was smart enough to use the SIMD instructions.
Neat.
But say now we want to fill the array with a value other than the default. Simple enough. Let’s change the code and re-examine.
Struct32 s32 =
new(1, 2, 3, 4, 5, 6, 7, 8);
for (int i = 0; i < cache.Length; i++)
{
cache[i] = s32;
}L0000: sub rsp, 0x28
L0004: xor eax, eax
L0006: mov rdx, [rcx+8]
L000a: cmp dword ptr [rdx+8], 0
L000e: jle short L006f
L0010: mov rdx, [rcx+8]
L0014: mov r8, rdx
L0017: cmp eax, [r8+8]
L001b: jae short L0074
L001d: mov r10d, eax
L0020: shl r10, 5
L0024: lea r8, [r8+r10+0x10]
L0029: mov dword ptr [r8], 1
L0030: mov dword ptr [r8+4], 2
L0038: mov dword ptr [r8+8], 3
L0040: mov dword ptr [r8+0xc], 4
L0048: mov dword ptr [r8+0x10], 5
L0050: mov dword ptr [r8+0x14], 6
L0058: mov dword ptr [r8+0x18], 7
L0060: mov dword ptr [r8+0x1c], 8
L0068: inc eax
L006a: cmp [rdx+8], eax
L006d: jg short L0010
L006f: add rsp, 0x28
L0073: ret
L0074: call 0x00007ff921600da0
L0079: int3Now were settings the struct values explicitly. However, taking a look at our generated assembly, one would notice its quite different. The clever SIMD instructions have been replaced with 8 separate mov instructions. That cant be efficient. If we benchmark the two functions the results aren’t surprising.
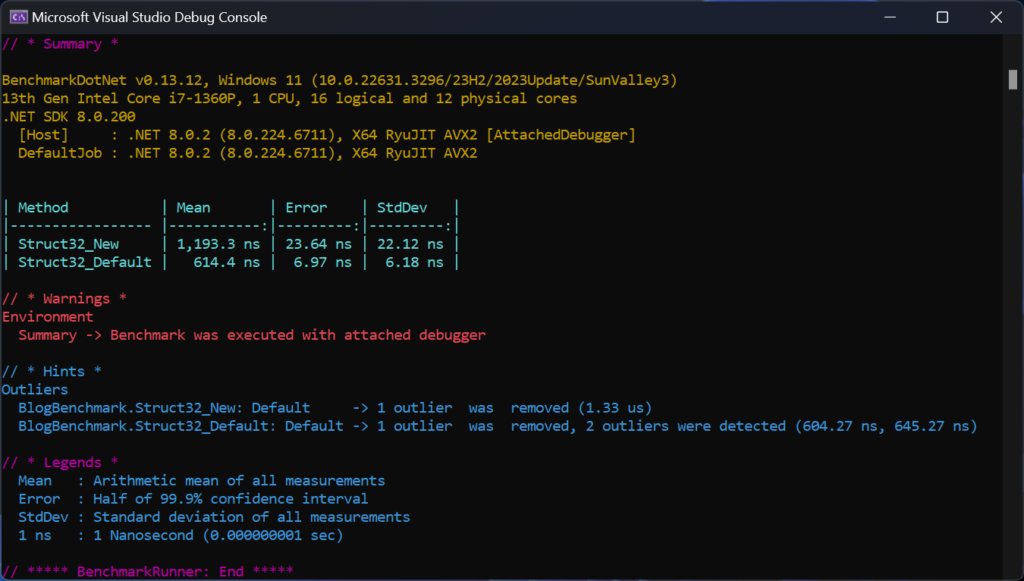
Almost 2 times slower. What happened?
Well the JIT eliminated the original s32 variable and it’s assignment. Deciding it best to apply the value directly to each element. Then it went a step further and decided to inline the ctor call on each element. Essentially changing the function to:
for (int i = 0; i < cache.Length; i++)
{
ref Struct32 target = ref cache[i];
target.a = 1;
target.b = 2;
target.c = 3;
target.d = 4;
target.e = 5;
target.f = 6;
target.g = 7;
target.h = 8;
}Which has decreased performance 2 fold. Here is the SharpLab de-compilation. Why would the compiler do such a thing. A simple solution here would be to disallow in-lining on our constructor like so:
[MethodImpl(MethodImplOptions.NoInlining)]
public Struct32(int a, int b, int c, int d, int e, int f, int g, int h)
{
this.a = a;
this.b = b;
this.c = c;
this.d = d;
this.e = e;
this.f = f;
this.g = g;
this.h = h;
}
Leave a Reply